Llama3简介:
llama3是一种自回归语言模型,采用了transformer架构,目前开源了8b和70b参数的预训练和指令微调模型,400b正在训练中,性能非常强悍,并且在15万亿个标记的公开数据进行了预训练,比llama2大了7倍,距离llama2的开源发布仅仅过去了10个月,llama3就强势发布,一起来看一下他的使用方法。
在这里我经过查询Meta公布的4月15日的基准测试结果,Llama 3 400B+模型的表现已经持平Claude 3 Opus,超过Gemini 1.5 Pro,仅在数学部分落后于最先进的 GPT-4 Turbo 2024-04-09模型。
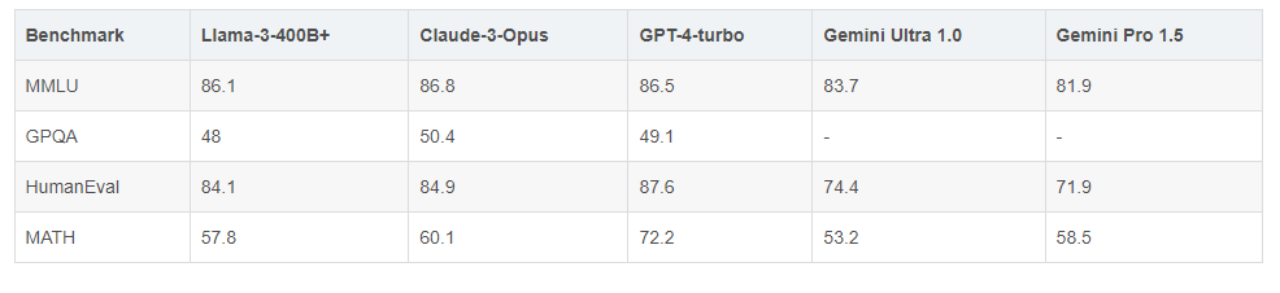
作为一个优秀团队的开源模型,我们更重要的是知道如何使用它,来减轻我们的负担,提升我们学习,完成任务,创作内容的效率与准确率。
Llama3安装:
git clone 安装
Llama3的git地址是 https://github.com/meta-llama/llama3 ,可以直接git克隆到本地
git clone https://github.com/meta-llama/llama3
然后在根目录运行
pip install -e .
去metallama官网登录使用下载该模型 https://llama.meta.com/llama-downloads/
- 注册登录,您将得到一个电子邮件的网址下载模型。当你运行下载时,你需要这个网址,一旦你收到电子邮件,导航到你下载的骆驼存储库和运行下载。
- 确保授予下载的执行权限。
- 在此过程中,将提示您从邮件中输入URL。
- 不要使用"复制链接"选项,而是要确保从电子邮件中手动复制链接
本地运行
torchrun --nproc_per_node 1 example_chat_completion.py \
--ckpt_dir Meta-Llama-3-8B-Instruct/ \
--tokenizer_path Meta-Llama-3-8B-Instruct/tokenizer.model \
--max_seq_len 512 --max_batch_size 6
注意事项:
- 替换 Meta-Llama-3-8B-Instruct/ 你的检查站目录的路径Meta-Llama-3-8B-Instruct/tokenizer.model 找到了你的标记器模型.
- …–nproc_per_node 我们应该把它放在你所使用的模型的价值。
- 调整max_seq_len 和max_batch_size 必要时参数.
- 这个例子运行了 example_chat_completion.py 在这个存储库中找到,但是你可以将它更改为不同的文件。
- 根据你本身的硬件来调整max_seq_len 和max_batch_size参数
huggingface 平台下载
可以通过huggingface 平台下载(需要先进入huggingface平台申请,同意它的条款,)

然后先安装huggingface工具
pip install huggingface-hub
然后指定meta-llama/Meta-Llama-3-8B-Instruct
huggingface-cli download meta-llama/Meta-Llama-3-8B-Instruct --include “original/*” --local-dir meta-llama/Meta-Llama-3-8B-Instruct
然后transformer的使用
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model="meta-llama/Meta-Llama-3-8B-Instruct",
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
如果没有gpu的同学可以使用cpu device=cuda,计算性能会差一些
完整的使用方式:
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
基于ollama使用:
目前推荐使用ollama的8b,70b,instruct, text 其他量化模型是别的用户微调过的,建议使用原生的llama3.
执行:
ollama run llama3:instruct
或者
ollama run llama3 (ollama pull llama3:8b)
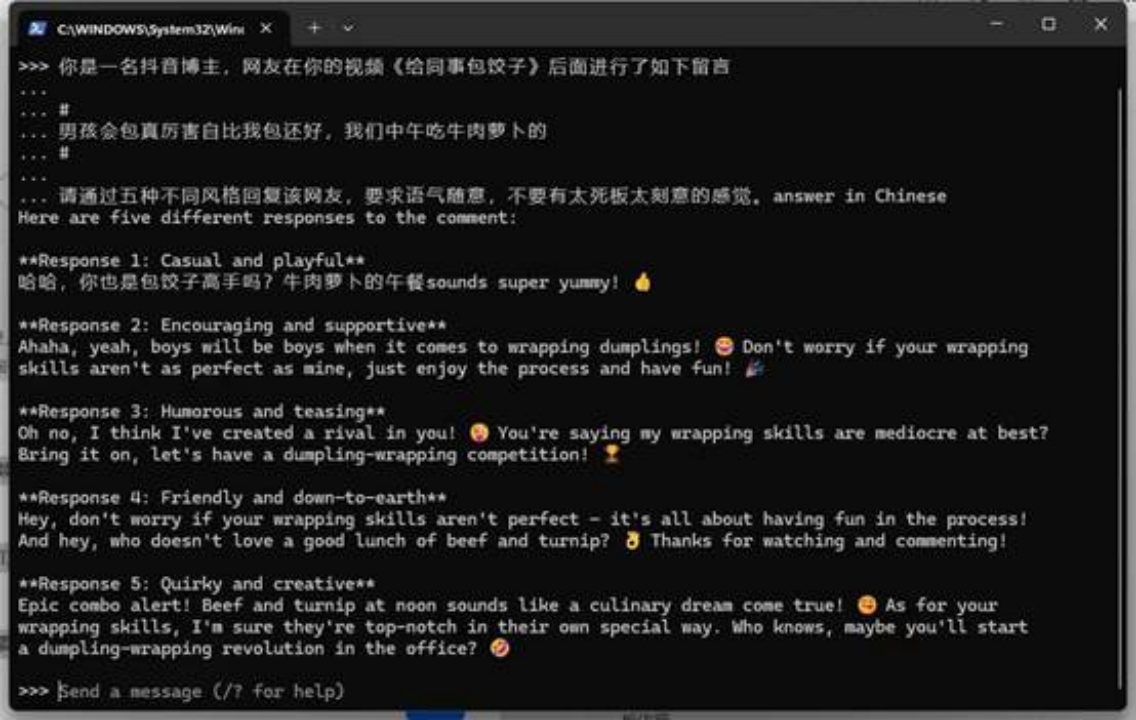

测试llama3的生成速度非常快,至少是llama2的两倍,如果有强大的显存支持效率会更高。
总结
llama3在llama2的基础上实现了质的飞跃,已经超过chat3.5的性能,并且他的预训练和微调是目前市面上开源的参数规模最好的,不仅是对于开发者还有企业使用者,这都是非常合适的一个模型。
下表显示了我们的评估结果与Claude Sonnet、Mistral Medium和GPT-3.5相比,在这些类别和提示上的汇总结果
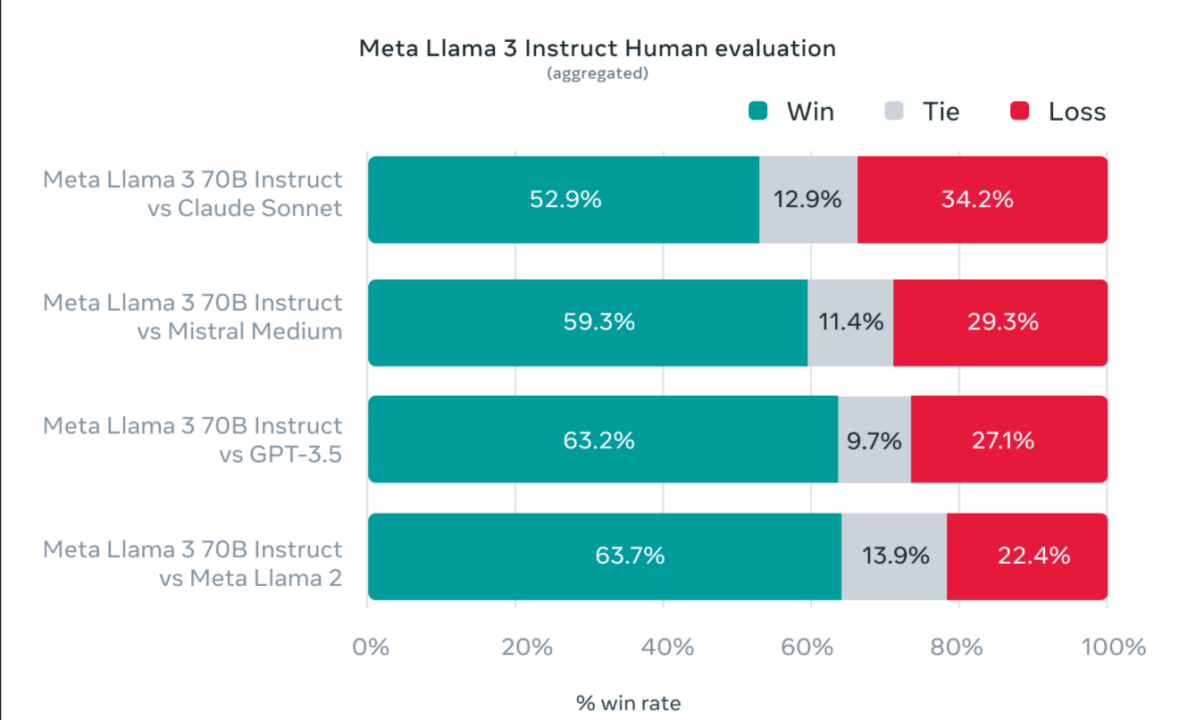
在未来的大模型道路上,选择最优秀的模型往往是我们第一步需要考虑的事情。